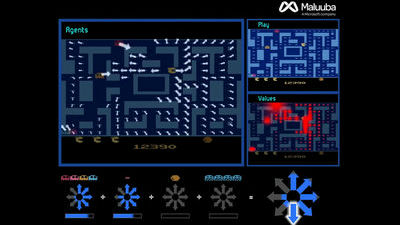
AIのマルチタスク学習時に生じる報酬の差異を埋めるための技術「PopArt」をDeepMindが開発

Google傘下の人工知能研究企業・DeepMindといえば、中国最強棋士を打ち負かした囲碁AIの「AlphaGo」や、ゲームを自ら学んで人間以上のプレイをするAIの「DQN」を開発した企業です。そんなDeepMindが、単一のエージェントに複数の物事を学習させる際に役立つ技術「PopArt」を開発しており、その効果を明かしています。
Preserving Outputs Precisely while Adaptively Rescaling Targets | DeepMind
https://deepmind.com/blog/preserving-outputs-precisely-while-adaptively-rescaling-targets/
単一のエージェントが多くの異なるタスクの解決方法を学ぶことを可能にするのが「マルチタスク学習」です。このマルチタスク学習は人工知能(AI)研究における長年の目標となってきました。近年になって登場した、Googleが開発する人間よりも上手くゲームをプレイできる「DQN」のようなエージェントでは、複数のゲームをプレイすることを学ぶために、このマルチタスク学習というアルゴリズムが使用されています。AI研究がより複雑化するにつれ、AI研究では複数の専門エージェントを設けることが主流となっています。一方で、各エージェントを学習させるために使用されるアルゴリズムは、より複数のタスクを単一の汎用エージェント上に構築できることが重要になるそうで、そこで重要になるのがマルチタスク学習アルゴリズムというわけです。
しかし、そんなマルチタスク学習アルゴリズムにも課題は存在します。そのひとつは、強化学習エージェントが成功を判断するために使用する報酬尺度には、それぞれ差異があるという点です。例えば、DQNにゲームのポンについて学習させる場合、エージェントは各学習ステップごとに「-1」「0」「+1」のいずれかの報酬を受け取ります。しかし、パックマンをプレイする場合、各学習ステップごとに数百もしくはそれ以上のポイント(報酬)を獲得することが可能となってしまい、同じ報酬尺度ではどのタスクが重要なものなのかを測れなくなってしまうというわけです。また、個々の報酬の規模が同等であっても、報酬の頻度が異なるなど、さまざまケースが考えられます。エージェントは大きなスコア(報酬)を持つタスクに集中するという性質を持っているため、報酬尺度や頻度が異なれば、特定のタスクでのみパフォーマンスが向上し他のタスクではパフォーマンスが低下するというケースが発生します。
こういった問題を解決するため、各ゲームで得られる報酬の規模にかかわらず、エージェントがゲームを同等の学習価値で判断できるように、各ゲームの報酬規模を標準化するための技術「PopArt」をDeepMindは開発しました。DeepMindによると、最先端の強化学習エージェントにPopArtを適用することで、57種類以上の多種多様なゲームを1度に学習できる単一のエージェントを生み出すことに成功したとのことです。

ディープラーニングはニューラルネットワークの重み付けが更新されることで、出力が目標の値に近づくようにするというものです。これは深層強化学習上でニューラルネットワークが使用される場合においても同じです。そこで、PopArtは学習対象のゲーム内スコアなどから平均値と普及率を見積もることで、スコアを標準化することを可能にするという技術。スコアを標準化することでスケールとシフトの変化に対して、より安定した学習が可能になるとのことです。
これまで、AI研究者たちは強化学習アルゴリズムでは報酬クリッピングを使用することで、報酬のスケール変動問題を克服しようとしてきました。これは、大きなスコアを「+1」、小さなスコアを「-1」と大まかに分類することで、報酬を標準化するという手法です。報酬クリッピングを用いることでエージェントの学習は簡単なものになりますが、エージェントが特定の動作を行わなくなるケースがあるとのことで、その様子をわかりやすく解説しているのが以下のムービーです。従来の方法である報酬クリッピングが、マルチタスク学習においては最適な方法ではないことがよくわかります。
Unclipped rewards using PopArt - YouTube
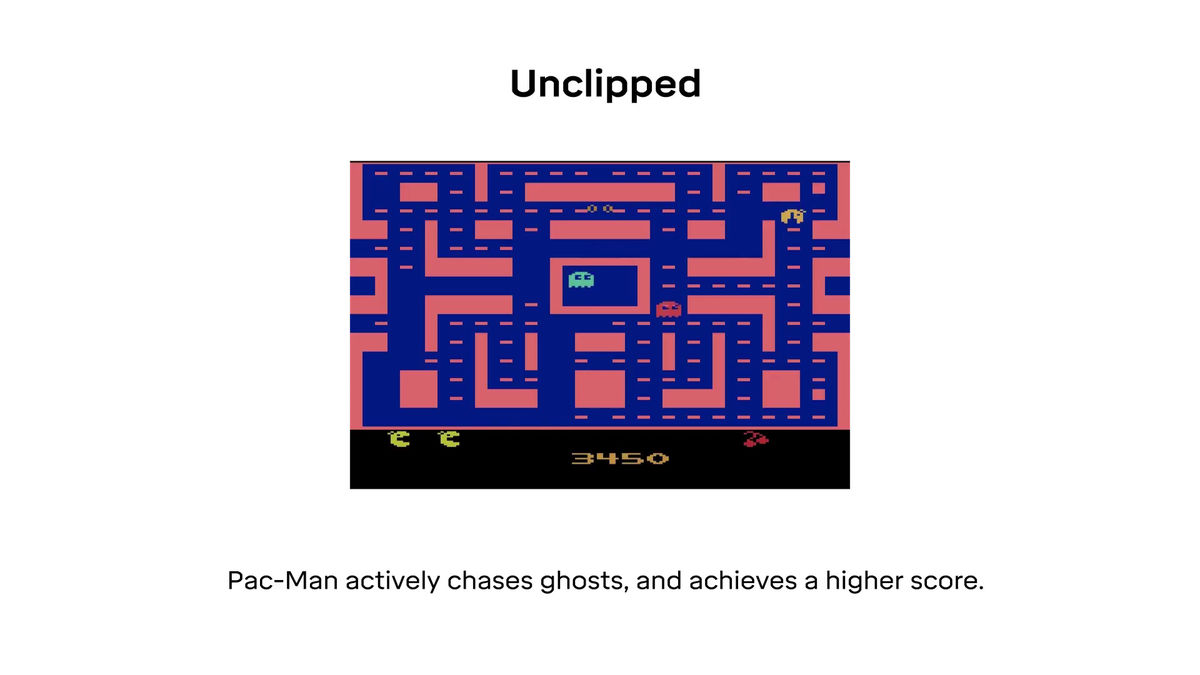
パックマンのゲーム目的はなるべく高いスコアをたたき出すことです。

パックマンでポイントを得る方法は2つあり、ひとつはステージ中に存在するドットを食べること。もうひとつはパワーエサを食べて、モンスターを食べることです。

ドットを食べると10ポイント

モンスターを食べると200~1600ポイントが得られます。

報酬クリッピングを用いた場合、ドットで得るポイントとモンスターを食べて得るポイントの間に違いを見出せなくなり……

より高いポイントをゲットできるモンスターを食べようとしなくなってしまうそうです。

それに対して、報酬クリッピングをやめてPopArtを適用すると、報酬が標準化されることでエージェントがモンスターを食べることの重要性を認識できるようになり……

追いかけてでもモンスターを食べて高ポイントを得ようとするようになります。
DeepMindで使用されているエージェントの中で最も普及しているもののひとつが「IMPALA」です。このIMPALAにPopArtを適用したところ、エージェントのパフォーマンスを大幅に改善することに成功しており、その成果は以下のグラフを見れば一目瞭然です。
以下のグラフは、各エージェントが57種類のゲームをプレイした際のスコアの中央値を示したもの。縦軸がスコア、横軸が学習時間を示しており、緑線がPopArtを適用したIMPALAのスコア、青線が報酬クリッピングを使用しない場合のIMPALAのスコア、青点線が報酬クリッピングを使用したIMPALAのスコアです。

DeepMindは「この種のマルチタスク環境で、単一のエージェントを使用してここまで高いパフォーマンスを記録したのは初めて」と記しており、さまざまな報酬を用いてさまざまな目的についてエージェントに学習させる場合は、PopArtが大きな力を発揮するとしています。
・関連記事
囲碁AI「AlphaGo」や「DQN」の開発元DeepMindが「スタークラフト2」で最強のAI構築に挑戦中 - GIGAZINE
Googleの人工知能「DQN」が人間より上手にプレイできるゲームとできないゲームの境界線 - GIGAZINE
Googleの人工知能「DQN」で主人公がすぐ死ぬゲーム「Montezuma’s Revenge」をプレイさせてみた結果こうなった - GIGAZINE
ゲームを自ら学んで人間以上に上達できる人工知能「DQN」が人間を脅かす日はいつくるのか? - GIGAZINE
・関連コンテンツ