
こんにちは、Data Labs の Data Analysis チームで主に LINE のメッセンジャーアプリに関する分析を担当している Takaguchi です。この記事は LINE Advent Calendar 2018 の2日目の記事です。
Data Labsは、LINE アプリをはじめとするLINEファミリーサービスのデータを事業へ活用するための専門的な開発組織です。私の所属するData Analysisチームでは、最新の知見を業務に取り入れるべく研究論文の紹介や研究会への参加などを積極的に行っています。
その一環として、「エンジニアは、国内外のカンファレンスへの参加に必要な費用を一年に一回は会社に負担してもらえる」という LINE の制度を利用して、国際会議 KDD 2018に参加しました(同僚の Takayanagi と私による参加レポート記事はこちらです)。この記事では、この国際会議に参加して最も強く印象に残った論文の内容を紹介します。
はじめに
この記事で紹介する論文の情報は以下の通りです(以下では「本論文」と呼びます)。
Alex Deng, Ulf Knoblick, and Jiannan Lu (Microsoft Corporation),
"Applying the Delta Method in Metric Analytics: A Practical Guide with Novel Ideas",
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Pages 233-242.
(https://doi.org/10.1145/3219819.3219919)本論文が強く印象に残った理由は、次の3点に要約できます。
- 鍵となる数式が非常にシンプルである
- 複数の実用的な問題に応用している
- 企業の実サービスに関するデータを使わずに論文を書いている
以下では、詳細な内容の説明を交えながらこれらの3点について順番に解説します。
1. 鍵となる数式が非常にシンプルである
数理的な内容に入る前の準備として、まず本論文のモチベーションについて説明します。
本論文が考える問題は、「複雑な統計指標の信頼区間を効率的に推定すること」です。観測されたデータに対して統計指標を計算するとき、一般的にその指標の値は観測するたびにばらつきます。よって、統計指標の値に基づいて再現性のある判断をするためには「ランダムに起こり得るばらつきの範囲」を見積もる必要があり、その見積もり方の代表例が信頼区間です。
平均値や標準偏差などの標準的な統計指標については、信頼区間を求めるための方法論が統計学において確立されています。
それでは、もっと複雑な統計指標についてはどうでしょうか。複雑な指標の一例として本論文で取り上げられているのは、2群の平均値の相対的な変化です。現実的な状況設定で言えば、A/B テストにおける統制群と処置群でのとある変数の標本平均に対して、以下の指標の信頼区間を推定したいということです。

この指標は処置による相対的な伸び率を表すので、テスト結果のビジネス判断という実用において意義のあるものです。しかし、データ分析を専門とされる方でも「上記の指標の信頼区間を推定しなさい」という問いに即答するのは難しいのではないかと思います(私はできません)。
この問題に対して、本論文では Delta Method と呼ばれる数理的手法を用いたアプローチを取ります。 Delta method の核心を口語で表すと、

というものです。
変数が1次元の場合について、数式を使いながら詳しく見てみましょう。 まず、データ点数を大きくするともとの変数が正規分布に従うということは、
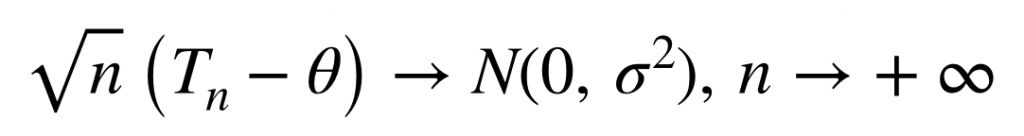
と書けます。なお、1つめの "→" は分布収束を表します(以下の類似する式についても同様です)。
次に、変換 Φ が微分可能であるとして、変換後の変数を極限値の周りでテイラー展開します。
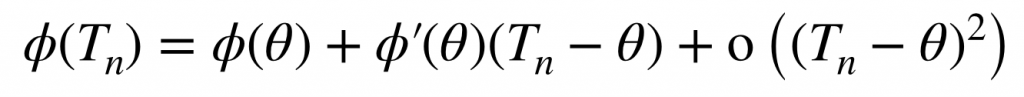
上記の2つの式を組み合わせると、以下の通り変換後の変数もまたデータ点数を大きくすると正規分布に従うことが言えます。

これが1次元の場合の Delta method です。
これだけでは、「平均値の相対的な変化の信頼区間を推定しなさい」という元々の問いにどうつながるのか、まだまったく分かりませんね。 もう少しだけ辛抱いただいて、多次元の場合についてもDelta method が成り立つことを確認するとゴールへ到達します。 導出の詳細は割愛しますが、もとの変数が2次元以上で漸近的に多変量正規分布に従うとき、以下が成り立ちます。
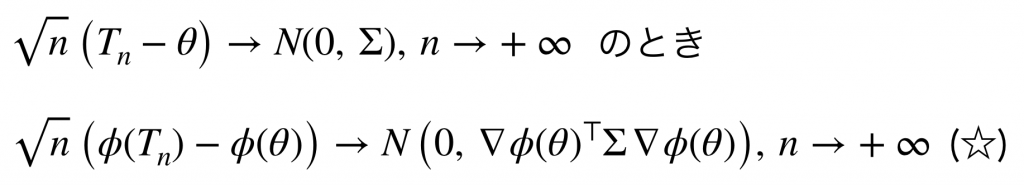
ここで変換 Φ は微分可能であれば変換先の次元は問わないので、たとえば2次元から1次元への変換でもよいというのがポイントです。
いま考えている「平均値の相対的な変化の信頼区間を推定しなさい」という問題に合うように、式(☆)へ具体的に設定を当てはめてみましょう。
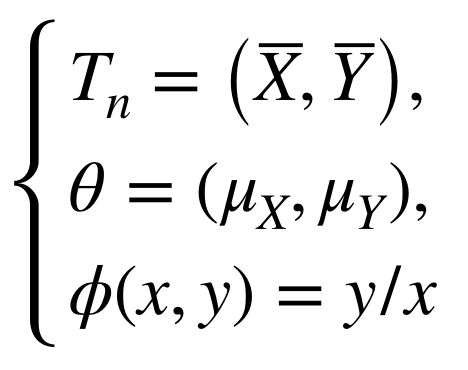
をそれぞれ式(☆)に代入してみると、

となります。つまり、データ点数が十分に大きいとき平均値の比のばらつきが正規分布に従うとみなせます。いま注目している平均値の相対的変化は (平均値の比 - 1) に等しいので、その信頼区間を教科書通りの方法で求めることができます。それに加えて、収束先の正規分布の分散がデータから簡単に計算できる形になっていることも実用上うれしい点です。
本論文の数学的なエッセンスはこれだけです。手順を追って見てきました通り、確率統計と解析のごく基本的な操作だけで導くことができる非常にシンプルな数式です。本論文の貢献は、一見まったく異なる複数の複雑な指標をこの「正規分布に従う2つの平均の比」の形に落とし込む変換の方法の妙にあります。
2. 複数の実用的な問題に応用している
前節で、本論文の手法を説明するために「2群の平均値の相対的な変化」という指標を例にとりました。 本論文ではこれ以外にも3つの指標について提案手法の応用が示されており、以下ではそのうちの1つ「ランダム化の単位と集計の単位が異なる指標」をご紹介します。 ここで紹介しない残りの2つも実務ですぐに使えそうな事例ばかりなので、関心のある方はぜひ原論文をご参照ください。
「ランダム化の単位と集計の単位が異なる指標」を説明するために以下の例を考えます。ウェブサービスのユーザーレベルでの A/B テストを実施していて、あるボタンがクリックされるかどうかに注目しているとしましょう。このとき、一方のユーザー群について「全ウェブセッションの中で注目するボタンがクリックされるセッションの割合」の信頼区間を求めることを考えましょう。
一般的にはユーザー1人あたりに複数のセッションがあり、さらにはセッション数はユーザーによって異なると考えられます。これはランダム化の単位と集計の単位が異なる例になっています。具体的にはユーザーがランダム化の単位でセッションが集計の単位です。この状況は、集計の単位がかたまり(cluster)になってランダム化の単位に紐づいていることから、cluster randomization と呼ばれます。cluster randomization では集計の単位が独立で同一分布に従う (i.i.d.; independent and identically distributed) という仮定が適用できず、標準的な方法で指標の信頼区間を推定することはできません。
それでは、「正規分布に従う2つの平均の比」の形に落とし込むというアプローチで問題を見てみましょう。ここでは以下の通り必要な記号の定義と仮定を行います。

変数のイメージを図に表すと以下のようになります。

上記の定義のもとで、求めたい「全ウェブセッションの中で注目するボタンがクリックされるセッションの割合」は

と表されます。ここで右辺の分子について記号を置き換えると

となり、信頼区間を求めたい指標が2つの平均の比の形になりました。 仮定から分母にある確率変数は群全体で i.i.d. なので、ユーザー数が十分大きいときこの指標は「正規分布に従う2つの平均の比」とみなせます。
最終的にこの指標の分散は以下の形で見積もられ、分布の正規性により信頼区間も直接的に計算できます。
この式を見ると、注目する指標の分散に対してユーザーごとのセッション数の分散がプラスに寄与することがわかります。言い換えると、cluster randomization ではなく群全体でセッションが i.i.d. だと単純化してしまうと、ユーザーごとのセッション数の分散に当たる項の分だけ指標の分散を過小評価してしまうことになるのです。
3. 企業の実サービスに関するデータを使わずに論文を書いている
本論文の中では、数値的にシミュレートした人工データに対して提案手法を適用することにより、その有効性を検証しています。
逆に言えば、企業の実サービスに関わるデータは一切使用されていません。
もちろん提案手法が実務レベルで有用であることは主張されており、Microsoft による「ExP」というオンライン A/B テスト基盤に実装済みであるそうです(本文2ページ目、1.3節の冒頭を参照のこと)。
この分野における企業発の研究論文といえば、研究機関のいち研究室では保持しえない規模の潤沢な計算リソースを活用したものか、実サービスのデータに適用して有用性を主張するもの(もちろんクリティカルな数値は隠した上で)、という先入観がありました。実際のところ、本論文が発表されていた Applied Data Science セッションの他の論文では、これらの2条件のうち少なくとも一方を満たす論文が多かったように見受けられました。
本論文は、統計学では古くから知られた手法を巧みに現代的な文脈に落とし込むことで、実データを使わずして最難関の国際会議に採択されています。
その手際の鮮やかさに、こういう成果の示し方もあるのだと感銘を受けました。
同時に、彼我のレベルの違いをまざまざと見せつけられたという感もあり、今後も一生懸命キャッチアップしていこうという思いを新たにしました。
おわりに
この記事では、"Applying the Delta Method in Metric Analytics: A Practical Guide with Novel Ideas" という論文について内容を紹介しました。
この論文の提案手法は数学的には非常にシンプルですが、現代的なビッグデータ分析の文脈にうまく沿わせることで有用な知見を引き出しています。
企業の実務においては、学術研究に身を置いていた時分には思いもよらなかったような研究のニーズに出くわすことがある、ということを私自身は日々実感しています。
この論文もそのような経緯で着想されたのかもしれないと想像をしながら読みました。
我々 Data Analysis チームにとって学術研究は本業ではありませんが、研究論文には日常的に接しています。
論文を読む主な目的は、(1) 既存の業務を効率化する(よりスマートな方法を知る)、 (2) 成果の精度を高める、(3) 落とし穴にはまらないようにする、この3つにあると考えています。
Data Analysis チームでは、誰かが論文を読んでそれで終わりではなく、皆にとって有益な知見はチーム内のパッケージや内製ツールに取り込まれて仕組み化される体制が整っています。この点はこのチームの大きな強みであると感じています。
この記事で紹介した Delta method についても、エンジニアのYutaniと一緒にパッケージへ実装する予定です。
最後に、Data Analysis チームでは、プロジェクトマネージャー・データサイエンティスト・データアナリストのポジションを積極採用中です。ご興味のある方はぜひご応募をご検討ください!
明日は Keiji Yoshida さんによる「データエンジニアリング関連ソフトウェアの障害対応事例 2018」です。お楽しみに!