
Data Science Team / B2B Data Engineering TeamのBukawa, Tanigawa, Yoshinagaです。
LINEでは、最新の知見を業務に取り入れるべく論文の紹介や研究会への参加などを積極的に行なっています。
その一貫として、LINEの社員が技術に関連する海外カンファレンスに会社負担で参加できる制度があります。
その制度を利用して2019年8月4日〜8日に開催された国際会議KDD 2019に聴講参加してきた内容について報告します。
Overview

KDD は Knowledge Discovery and Data Mining の略称で、アメリカ計算機学会(ACM)が主催する機械学習やデータマイニング関連の国際会議です。
理論的な研究を対象とするResearchトラックに加えて、企業での事例など実問題への適用を対象としたApplied Data Scienceトラックが設けられていることが特徴です。
投稿数は,Researchトラックは1179件、Applied Data Scienceトラックでは670 件で、どちらも過去の記録を更新しました。
Researchトラックの採録数は、全体で163件 (採択率14.8%)、口頭111件 (9.4%)、ポスター63件 (5.3%)で、Applied Data Scienceトラックでは全体で147件 (22%)、口頭47件 (7%)、ポスター100件 (15%) でした。
講演者と参加者ともに企業に所属する人の割合がとても高い印象で、学術とビジネスの垣根が非常に低いことを実感しました。
本会議への企業スポンサーの規模にもこの研究分野に対する企業の大きな期待感が現れており、50社以上の企業がスポンサーとなっており、100万ドル以上を集めていました。

(なお、サンディエゴで開催のKDD2020は例年より1日長い6日間の開催となるようです)
参加したセッションの概要
KDD は多数のセッションが同時並行で進む大規模な会議なので、焦点を定めて聴講する必要があります。
そこで、会議全体を通じて
- Tanigawa: 「因果推論 / ABテスト」
- Yoshinaga 「異常検知 / KPI予測」
- Bukawa: 「広告領域のデータ分析」
を各々の個人的なテーマとして設定し、会議を聴講してきました。
以下、この3人の視点から印象に残ったセッションを順に紹介します。
※ スライドは各講演リンク先に掲載されているプレゼンテーション資料より引用
Tanigawa's viewpoint
私たちが所属するデータサイエンスチームでは、サービスに関する意思決定をするための分析やABテストの設計・評価を日々行なっています。今回のKDDでは、最近、個人的に興味がある"因果推論"と実務で活かしやすい"ABテスト"の分野を中心に聴講してきました。
1日目のTutorialでは、Hypothesis Testing and Statistically-sound Pattern Mining と Challenge, Best Practives and Pitfalls in Evaluating Results of Online Controlled Experiments を聞いてきました。
Hypothesis Testing and Statistically-sound Pattern Mining
このTurorialでは、対立仮説や帰無仮説の定義および検定力などの基本的知識に加え、独立性の検定や多重比較検定を中心に紹介されていました。
独立性の検定については、Fisherの正確確率検定やカイ二乗検定が有名ですが、適用するデータによっては、それよりも制約を弱めたBarnard検定の利用も検討すべきであることを説明されていました。また、多重比較検定を行う際のP値の補正方法や、統計的有意パターンマイニングの分野で利用されるLAMPやPermutaiton Testなどの手法も取り上げられていました。
検定を行う際には、各検定がどのような仮定をおいているのかを改めて理解した上で、適切な手法を用いる必要があることを実感しました。

Challenge, Best Practices and Pitfalls in Evaluating Results of Online Controlled Experiments
近年、UIの変更から機械学習モデルを利用したパーソナライズまで、様々な種類のA/Bテストが行われています。A/Bテストを行う際は、検証したい仮説を元に、テストの良し悪しを判断するための評価軸を適切に設定し、ユーザ行動の変化を知る必要があります。このTutorialでは、Microsoft・SnapChat・Outreseach・FacebookのData Scientistの方々が、評価軸の考え方について、実例を元にレクチャーされていました。
前半のIntoroductionでは、A/Bテストを行う必要性や、A/Bテストの評価軸を考える際に利用できるフォーマットについて紹介されていました。以下のようなフォーマットを埋めた後、フォーマット内の仮説を検証するための評価軸をより効率よく適切に判断しやすくなるそうです。

後半のBest Practices for Evaluating Experiment Resultsでは、正しいOEC(Overall Evaluation Criteria:A/Bテスト全体の結果を評価するメトリクス)を設定するために、正しい評価メトリクスとしての性質を5つ定義し、その性質を満たすメトリクスの作成に役立つフレームワークをいくつか取り上げています。また、評価メトリクスだけでなく、A/Bテストの最中に起こりうるレイテンシの低下や、想定外のユーザ行動にも注意する必要があることに言及していました。
一貫して実サービスに適用できる内容が多々あり、今後のA/Bテストで積極的に取り入れていきたいです。
2日目〜5日目の本会議では、Yoshinaga、bukawaと同様に、Applied Data ScienceセッションおよびApplied Data Science Invited talkセッションを中心に参加しました。
ここでは2つの論文と1つのInvited Talkを取り上げて内容を紹介します。
Improve User Retention with Causal Learning
Webサービスでは、離反しそうなユーザに対してクーポン配布などのプロモーションを打つことで、ユーザのリテンション率を高める施策を行うことがあります。このような場合、ユーザの離反予測を行なったり、uplift modelingなどを利用したりすることで、より介入効果の大きいユーザに対して優先的にクーポンを配ることが多いです。しかし、プロモーション施策自体の費用対効果について焦点を当てると、「より介入効果の大きいユーザにプロモーションを打つこと」だけでなく、「プロモーションコストが予算内であること」も重要になります。
この論文では、プロモーションコストの予算とプロモーション対象者の割合が制約として与えられた上で、より介入効果の大きいユーザにプロモーションを打つことを目的としたアルゴリズムを提案しています。
具体的には、以下のような方法で、リテンション率/コストで表されるランキングスコアを求めるためのモデルを学習しています。
Step1:Lasso回帰とCausal Forestを利用して、各ユーザのリテンション率とコストの介入効果を予測
Step2:step1で求めたリテンション率とコストが与えられた下で、「プロモーションコストが予算内であること」を制約条件に含めた以下のような0-1ナップサック問題に、ラグランジュ緩和を適用して、連続緩和問題を解いている。これにより、各ユーザに対して、リテンション率/コストで表される効率値を求めることができ、それをプロモーション適用の優先順位を決めるためのランキングスコアとして利用している

Step3: Step2で得たランキングスコアを予測する学習モデルを作成
この論文の著者がUberの方で、実際に1回の乗車で利用可能なクーポンをユーザに発行して、A/Bテストを行なった結果について紹介されていました。1週間に1回以上クーポンを取得したユーザを対象に、のち1ヶ月間におけるユーザのリテンション率やかかったコストのデータを収集し、モデルの学習・パラメータ調整・モデルの評価のために利用したそうです。上記のアルゴリズムに対して、Lasso回帰・Causal Forest・MLPを適用して、プロモーション費用とリテンション率の効率性を反映したCost Curveという指標を利用して効果測定を行なっていました。
リアルなビジネス問題の制約を適用されていて、とても興味深い論文でした。プロモーションコストがユーザによって異なる状況の場合には、有効な手法だと思いました。この論文で取り上げているプロモーション施策におけるユーザ選択は、今後も業務で取り組む可能性があると思うので、参考にしたいです。
The Identification and Estimation of Direct and Indirect Effects in A/B Tests through Causal Mediation Analysis
Esty.incはEコマースのサービスです。オーガニックサーチ・スポンサードサーチ、レコメンデーションなどを提供していますが、モジュールの中身は違っていても、ユーザからは同じような機能に見えます。これらのモジュールの改善をして、ユーザーの全体的な体験を最適化したい場合、各モジュールを個別に理解して改善するのではなく、どのモジュールの変更が最もユーザーの行動を変えたのか、洞察を得る事が重要になります。
例えば、レコメンドモジュールでA/Bテストを行った際、以下のような結果が得られたとします。
・レコメンドモジュールでのクリックは有意差ありで増加
・オーガニックサーチのクリック数は有意差ありで減少
・サイト全体のCTRは有意差なしで増加
このような場合、レコメンドモジュールの直接的効果とオーガニックサーチからレコメンドモジュールへの間接的効果が相殺されてしまうことで全体的な効果が薄まり、レコメンドモジュールのテストパターンを本番に適用して良いのか判断に悩む可能性があります。
そこで、本論文では、媒介分析を利用して、この直接的効果と間接的効果を分割する方法を提案し、直接効果のみをA/Bテストでの評価とて利用することを推奨しています。
既存手法として、Sequential Ingorabilityという媒介変数と結果変数の関係性に対する仮定のもとで、直接効果・間接効果の平均を推定する方法が提案されています(Imai et al. 2010)。しかし、Sequential Ingorabilityは実験によって成り立たないことも多く、仮定が成り立たない場合でも、直接効果・間接効果の平均を推定することができるGADEとGACMEという手法を提案しています。実際にEstyのABテストで提案手法を適用した結果についても紹介されていました。
論文で紹介されているABテストの事例はよくある話だと思うので、適切に媒介分析を活用していきたいです。
Friends Don’t Let Friends Deploy Black-Box Models: The importance of intelligibility in Machine Learning
この Invited Talkでは、Microsoft Reserchの上級研究員であるリッチ・カルアナ氏が、医療関係のデータにおける意思決定についてお話しされていました。
機械学習手法を適用するにあたり、精度と解釈性はトレードオフな関係性であることが知られています。医療関係のデータを扱う際は、作成したモデルを解釈→検証→編集という手順を踏みながら、最終的には信頼できるようなモデルであることが重要らしく、今までは精度は低いが解釈性のあるモデルを選択されていた事が多かったそうです。しかし、最近では、GA2Mと呼ばれるGeneralized Addtive Model(一般加法モデル)の一つで、相互作用項を含めた「Genelized Additive Model with Pairwise Interactions」という手法がMicrosoft Inc.によって開発されました。医療関係のデータでは、実際に医療を受けている人のデータが入っているため、すでに介入効果のあるデータが取得されてしまうので、GA2Mで作成したモデルを解釈しながら、修正を重ねていく必要があるという話でした。
後から知ったのですが、このInvited Talkのタイトルと同じ内容が、Youtubeでも公開されているようなので、詳細を知りたい方はご覧ください。

Yoshinaga's viewpoint
B2B Data Engineering Teamでは「Data Scientist kills Data Science」の精神のもと、データサイエンティスト以外でも簡単に使えるAPI (Data Science API) の開発を行なっています。
APIの利用者にデータサイエンスを感じさせず、利用者の業務に注力できるようにすることが目的です。現在は、特に異常検知とKPI予測の開発に注力しています。APIの元となるモデルは、精度が高いことはもちろん、汎用的である(様々な状況で柔軟に使える)ことが求められます。
そこで、「柔軟な仕組みを作るために活かせる研究・事例はないか」という観点で各セクションに参加しました。
以下では、聴講したセクションについて簡単に紹介します。
1日目のチュートリアルでは、Forecasting Big Time Series: Theory and Practiceというセッションに参加しました。
時系列予測、予測からの外れ値の検知を行うための方法論を広く扱った内容でした。
時系列の特徴・構造を理解するための分解方法、時系列どうしの類似度の評価方法、線形・非線形時系列の予測、深層学習による現代的なモデリング方法など様々なトピックがありました。良い予測のために、ドメイン知識の活用とモデリング方法の選択について適切な塩梅を見つけることが重要であることを強調されていました。
業務ではドメイン知識を活用して解釈性の高いモデリング方法を選択することが多かったのですが、ブラックボックス的ではある一方でより柔軟に構造を学習できる方法も適切に活用していこうと思いました。

2日目のワークショップはAdKDD & TargetAdというセッションに参加しました。詳細な紹介は同チームのBukawaが担当しておりますので、こちらでは割愛します。
AlibabaのDisplay広告配信プラットフォームの紹介やBayesian Personalized Rankingを使ったアプリ内課金 (LTV) 最大化のためのアプリ広告配信の方法から、動画の中で適切な枠を推定して広告商品を自然に差し込むといった非常にチャレンジングな内容まで幅広く扱うセッションでした。
特にInvited TalkのTencent Adの内容は圧巻で、広告の未来を垣間見た瞬間でした。
3日目〜5日目の本会議はTanigawa, Bukawaと同様にApplied Data ScienceセッションおよびApplied Data Science Invited talkセッションを中心に参加しました。ここでは、以下の3つの内容を取り上げて紹介します。
Time-Series Anomaly Detection Service at Microsoft
Microsoft Inc. は大企業向けに時系列データの異常検知サービスを提供しています。本論文は、そのサービスのデータパイプラインと異常検知アルゴリズムに関する紹介をしています。
本論文の特徴は以下の2点です。
- 正確性・効率性・汎用性を意識したシステム設計
- 信号解析で知られるSpectral Residual (SR)に加えて、CNNを組み合わせる (SR-CNN) ことで高い検知性能を実現していること
Mircrosoft Inc. が提案しているシステムは、データの取り込み、実験のプラットフォーム、オンライン処理の3つの要素からなっています。
利用者は監視するサービスのログを指定するだけで、異常検知アルゴリズムの専門的な知識なしで高精度の異常監視が行えるようになります。
このシステムの構成は、私たちのTeamの考え方に近いため、今後大規模な監視システムの開発で参考にしたいと考えています。
さらに、提案モデルに関しても、Yoshinagaは比較手法のTwitter-ADを良く利用していたため、検知性能の違いに大きな感銘を受けました。
Mircrosoft Inc. のProduction Dataを使った実験では、他のOSSを利用した結果よりもF1 scoreが20%以上向上したとのことでした。
ただし、SR-CNNは教師あり学習のため、異常ラベルデータをある程度貯める必要があります (SRは教師なし学習)。
そのため、過去に異常が発生したデータセットならばSR-CNNを使って分類することが可能ですが、新規サービス開始後の監視ではすぐに使うことは難しいと思われます。実運用の際は、初期段階でSRによって検知・検知結果によるラベリングを行い、ある程度ラベリングができた段階でSR-CNNへ移行するというやり方がよいのではないかと思いました。
システム構成・機械学習手法の両方で非常に参考になる内容でした。


Auto-Keras: An Efficient Neural Architecture Search System
ニューラルネットワークの構造を最適化する方法として、Neural Architecture Search (NAS) があります。
NASの計算コストは、探索するネットワーク構造の数とそれぞれのネットワークの計算時間の平均の掛け算で理解できます。
しかしながら、これまでの手法は両者ともに計算コストが大きいものでした。
本論文では、"Network morphism"というネットワークの機能を保ったまま構造を変化させるという考え方を採用し、ベイズ的最適化を用いて探索の効率化を図っています。
まず、Network morphismにより過去の学習モデルを活用することで、それぞれのネットワークごとの計算時間を抑えることができます。
さらに、ベイズ的最適化によってネットワーク構造の探索も効率化をすることで、探索すべきネットワーク構造の数も小さくすることができます。
結果として、従来のNASの手法と比べてより短い時間で精度の高いモデルが作成できるようになっています。
本会議開催時点では、まだpre-releaseという状態でCNNなどの限られたネットワーク構造にのみ適用できる状態でしたが、将来はより多くのネットワークへの適用を検討しているようで、今後の発展が期待されます。
Auto-Kerasのコードとドキュメントは、以下のリンクから取得できます。
Sequential Anomaly Detection using Inverse Reinforcement Learning
逆強化学習を初めて異常検知の問題に適用した論文です。
逆強化学習とは、専門家が適切な行動をしていると仮定して、専門家の行動から最適な報酬関数を学習する方法です。
本論文では、正常パターンを専門家の行動として順序データの報酬関数を推定し、報酬の高さ(高いほど正常)で異常度を定義します。
また、一般的に逆強化学習は計算コストが高いのですが、ベイズ統計のアプローチを取り入れることで計算コスト・不確実性を抑える工夫をしています。位置情報の履歴データから異常行動を判定する実験では、比較手法よりも高い性能を示しておりました。
正常状態を専門家とみなすアイデアが挑戦的ではあるが面白いことと、実世界のデータで強化学習の有効性を示していた点に感銘を受けました。
Yoshinagaは以前の職場で強化学習の研究開発に携わっており、強化学習を実世界へ適用することに対する困難を経験しておりました。
そのため、本論文のような実世界のデータに対する強化学習の適用事例は、強化学習の基礎・応用研究を促進するものだと期待しています。
リアルタイムに異常判定する状況での活用が期待できるため、今後活用できる場面では本論文の方法を検討してみたいと考えています。
Bukawa's viewpoint
インターネット広告業界においてはわずかな予測精度の改善が直接的に会社の利益に結びつくことが多く、データ分析や機械学習の研究開発で培われた技術や叡智が徹底活用されており、各社がしのぎを削っています。
弊社では運用型広告配信プラットフォームである「LINE Ads Platform」を提供しており、ここにも多数のデータ分析や機械学習の技術が使われています。
そこで「より良い広告配信プラットフォームに活かせる研究はないか?」というモチベーションで各セッションに参加しましたので、それを簡単に紹介します。
1日目のチュートリアルでは、Tutorial on Social User Interest Mining: Methods and Applicationsというセッションに参加しました。
Tutorial on Social User Interest Mining: Methods and Applications
ユーザーの行動データからユーザーの関心を引き出すことは、オンライン広告などにとって重要です。
近年ではtwitter、Facebook等のソーシャルネットワークから引き出されるユーザーの興味が重要な意味をもち、これらを分析するための観点に関するこの分野の研究を包括的に紹介していました。
2日目は、ネット広告分野のワークショップであるAdKDD(今年からAdKDD&TargetAdの2つを統合)というセッションに参加しました。
普段は主にSSPサイドの立場での分析がメイン業務のため、AdExchange, DSP, Advertiser, Publisherと様々な立場での発表が聞けて面白かったです。
ペーパーと発表スライド(動画は今後アップロードされる予定)は以下のサイトに現時点(8月下旬)で概ねアップロードされています。
AdKDD2019 2019 Papers and Talks
https://www.adkdd.org/2019-papers-and-talks
Tencent Ads: Interesting Problems and Unique Challenges
最もインパクトがあったのは、Tencent Adsの発表「Tencent Ads: Interesting Problems and Unique Challenges」におけるVideoIn Adsでした。
動画内で広告を配置できる場所を検知し、元の動画のパースと調和するように広告オブジェクトにアングルを付けるなど調整し、さらに輝度、彩度、ぼかし、付影処理を施し、動画内に広告オブジェクトを埋め込んでしまう、というものです。
VideoIn Adsでは小口の広告スロットを作り出せるので、広告主は動画広告への出稿ハードルが下がるかもしれません。
一方、動画内に立体物を配置したい場合は、360度全方向からのクリエイティブを準備する必要があり、このVideoIn Adsだけの対応が発生します。
とにかくTencentの潤沢な開発リソースに圧倒されました。
現段階では動画中でのVideoIn adsには違和感を覚えましたが、これも近いうちに解消されていくだろうな、と容易に想像ができました。
1. 広告スロットの検知

2.広告オブジェクトのパース調整

3.輝度、彩度、ぼかし、付影処理

4.広告フォーマット
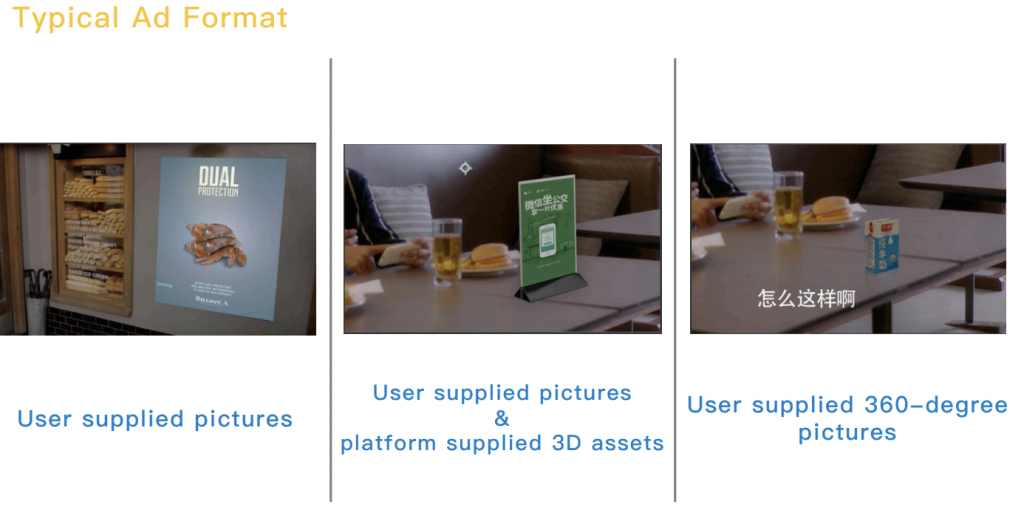
5.実際に埋め込まれた広告オブジェクト例
 |
 |
↑テレビ画面へCMが流れているように広告を埋め込む
3日目〜5日目の本会議では、Tanigawa, Yoshinagaと同様に、Applied Data ScienceセッションおよびApplied Data Science Invited talkセッションを中心に参加しました。
ここでは2つを取り上げて内容を紹介します。
TV Advertisement Scheduling by Learning Expert Intentions
熟練者の過去の行動履歴データから逆最適化し、属人的な業務の意思決定プロセスを自動化する仕組みをTV局のCM割当業務に適用したNECの発表です。
従来、テレビ局のCMスケジューリング担当者は月間700(そう仰っていた気がします)ほどあるCM枠に対して、番組とCMの組合せに対するノウハウ(広告主の好みや、料理番組中には殺虫剤のCMはNGなど制約等)を駆使し、調整していたとのことでした。
これらスケジューリング担当者の現在までのCM枠への割当を正として逆最適化を行い、業務効率化の仕組みを構築したという話です。
非常に面白い内容で弊社参加メンバーで聞き入ってしまいました。
業務効率化案件をやっているコンサル等から問い合わせがありそうな適用範囲が広く、すぐ活用されそうな内容だと思いました。
Seven Years of Data Science at Airbnb
Airbnbのデータサイエンス部門のディレクターであるElena Grewal氏の自身のキャリアとAirbnbでのデータ活用の発展段階を重ね合わせた講演でした。

↑講演の出だしはエモい
データサイエンスという意味には多様性があり、Airbnbでは3種類のスキルセットにわけているとのことでした。
1.分析
評価指標を決めたり、ビジネス課題を解決するようなデータ活用ストーリーを描くことができる
2.アルゴリズム
機械学習をプロダクトへ組み込むことができる
3.推論
因果関係の調査を行うことができる
役割を明確にさせることで、分析案件のおいて社内での意思疎通もしやすくなり、人材募集の際にもミスマッチが起きにくくなります。
ただし組織やサービスがまだ初期段階であれば、いきなりこのような役割分担をする必要はないようなことも言っていました。
さらにデータサイエンティスト以外の社員もデータを効率的に使って仕事ができるようにするため、Data Universityという社内プログラムも作成し、多くの社員が受講しているとのこと。
こうした方向性を明確に打ち出し、社内外へ伝えることはデータサイエンス部門のリーダーとしては非常に重要なことだと思いました。
加えて、組織やサービスのフェーズに応じて「データサイエンティスト」という役割は段階的に発展していくものであり、いま成功している企業の完成された状態をそのまま適用すべきではないということも再認識できたのもよかったです。
おわりに
本会議に参加したことによって、本研究分野における最先端の動向と人々の熱気を肌で感じることができました。
基礎研究だけでなく、企業の応用研究や最先端の技術の活用事例を通じて、我々のサービスを向上するための知見を多く得ることができました。
LINEでは、データサイエンティストを積極的に募集しています。最新の研究動向を学んで業務に活かせる機会がたくさんありますので、興味のある方はぜひ応募をご検討ください。
Appendix
大都市以外で開催された場合に懸念すべき点として、KDD2019で発生した宿泊施設に関する出来事を残します。
学術会議などのアカデミックイベントの運営と、参加者同士の交流をバックアップするイベントアプリ「Whova」がKDD2019では活用されていました(開催前日に突如メールで存在を知らされる)。
アンカレッジに向かう乗り継ぎの際に(日本からアンカレッジへの直行便はない)、アプリを弄っていたら日本人コミュニティの存在を発見したので眺めていたら下記の情報が…

我々も宿泊するAviator Hotelでオーバーブッキングが発生し、大学の寮に送り込まれるとのこと。
ホテルに着くとやはり受付には行列が発生しています。

↑やけに長い構造のAviator Hotel
並びつつ受付でのやりとりを眺めていると明らかにスンナリは泊まれなさそうな様子で不安が高まります。
いよいよ我々の番になりチェックインしようとすると、予約はちゃんとされているけど、オーバーブッキングが発生して用意できる部屋がないので他のホテルに連絡して部屋が用意できるか問い合わせているからしばらく待ってほしいとのこと(我々は大学寮は案内されなかった)。
待つ以外の選択肢もないので受付横で待ちつつ、自分たちでもホテルを検索しましたがKDD開催中のため当然取れるホテルもなく(会場から車で30分程度のところに1泊10万のロッジはAirbnbで見つけたが…)、加えて宿泊先で問題が発生した場合の緊急連絡先に一応問い合わせるがやはり何も解決しません。
そんなことをしつつも、受付横で見ているとたまに部屋を案内される客が発生していることに気が付きました。
特徴としては「なぜ泊まれないのか?」と粘っている客では…と気がついたあたりで、ゴリ押しすれば部屋は案内されるから頑張れ、とある日本人おじさんからアドバイスを貰いました。
なるほどですね、とすぐに実行するとあっさりと部屋を用意され、無事宿泊することができました。
ホテルでオーバーブッキング発生というのは初体験でしたが、特に対処できることもなく教訓もないのですが、あえて言えば小都市での開催は昼に到着する便で行ったほうよい、くらいでしょうか。
なお、KDDらしさを感じた点もありました。
Whovaに"Who is staying at Aviator Hotel?"というコミュニティが出来て、Aviator Hotelの問題点が共有され、そのなかの1トピックとしてオーバーブッキング問題も話されていました(他にはWi-Fiがつながらないとか掃除がされていないとか)。
そのコミュニティでExpediaやHotels.com経由(2つともExpediaグループのサービス)の予約でオーバーブッキングが発生しているのでは?という問題提起がなされると、颯爽となかの人が登場し、内部でエスカレーションするから予約番号を教えてくれ、というやり取りが発生する胸アツ展開になったりしていました。

↑夏のアンカレッジ、23時でこの明るさのため無限にビールを飲めそうな気分になりました