ログ調査基盤を構築してみた


こんにちは。
株式会社ココナラのインフラ・SREチーム所属の かず です。
システム運用において、有事の際に迅速かつ適切なシステム稼働状況の確認は欠かせません。
その手段の1つとして、ログの調査や分析の効率化は切っても切れない関係です。
システムが成長するにあわせ、ログの種類や量が多くなり、結果としてログの調査や分析が難しくなるのはよくある話かと思います。
弊社でもサービスのグロースに伴って、ログの種類や量が多くなり、結果としてログの調査や分析で課題を抱えていました。具体的には以下の2点です。
- ログから原因調査を行うには、複数ログを横断・突き合わせが必要
- ログの追跡に必要な情報がログに出力されない場合がある
そこで、課題への対応としてログ調査基盤の構築を行いました。
本記事では背景や苦労したこと、効果についてご紹介します。
- 複数ログの横断調査実現に向けて
- ログ調査基盤の構築
- 苦労したこと
- 効果
- まとめ
複数ログの横断調査実現に向けて
「トレースID」を定義する
システムで共通利用する「トレースID」を定義することで、複数ログに対する課題を解決しました。
「トレースID」の具体的な条件は以下になります。
- すべての通信経路において、トレースIDを取得できる
- URLへのアクセスやAPIへのリクエスト毎に、トレースIDが異なるものを取得できる
- 同一リクエストの内部処理においては、途中の処理で変わってはいけない
上記の条件を満たすものとして、ALBからHTTPヘッダーとして付与される X-Amzn-Trace-Id をトレースIDとして採用しました。(ココナラのプロダクトはAWSで稼働しています)
他には、nginxやenvoyでトレースIDを生成する案もありましたが、以下の理由で採用を見送りました。
- ミドルウェアが起点となり、システム全体のログを機械的に突き合わせできない
- QCDの観点でDelivery(納期)を最優先にしたかった
ログにトレースIDを記録する
ログにトレースIDを記録する事例として、nginxを例に上げてご紹介します。
ALBにて付与される X-Amzn-Trace-Id は、HTTPリクエストヘッダーに含まれます。
nginxでは http_ のprefixをつけることにより、HTTPリクエストヘッダーの値をログに記録[1]できます。
そのため、以下の設定を反映しました。
user nginx;
pid /var/run/nginx.pid;
http {
##
# Logging Settings
##
log_format coconala_json escape=json '{"time": "$time_iso8601",'
'"remote_host": "$remote_addr",'
'"method": "$request_method",'
'"path": "$request_uri",'
'"status": "$status",'
'"bytes": "$body_bytes_sent",'
'"sec": "$request_time",'
'"referer": "$http_referer",'
'"user_agent": "$http_user_agent",'
'"server": "$hostname",'
'"apptime": "$upstream_response_time",'
'"upstream_addr": "$upstream_addr",'
'"upstream_status": "$upstream_status",'
'"upstream_http_location": "$upstream_http_location",'
'"request": "$request",'
'"http_x_forwarded_proto": "$http_x_forwarded_proto",'
'"http_x_forwarded_for": "$http_x_forwarded_for",'
+ '"x_amzn_trace_id": "$http_x_amzn_trace_id",'
'"realip_remote_addr": "$realip_remote_addr"}';
access_log /var/log/nginx/access.log coconala_json;
error_log /var/log/nginx/error.log;
include /etc/nginx/conf.d/*.conf;
}
トレースIDをログへ出力するには設定ファイルへこの1行を追加するのみでできます。
ログへトレースIDを記録する以外で必要なこと
ココナラではユーザーの行動ログ分析などでBigQueryを利用しており、ログの改修を行う際には気をつけるべき点が2つありました。
- プログラムに
X-Amzn-Trace-Idを利用した通信の許可- 明示的に許可された値のみ、連携するプログラムに付与しているため
- BigQueryでのログ分析への影響調査
ココナラはマイクロサービス化しており、1つのURLアクセスやAPIリクエストへの処理に対して、システム内部にて複数回の通信が生じます。
そのため、同じトレースIDを同一のURLアクセス、APIリクエストの処理に対して同じトレースIDの値を付与する必要がありました。
具体的な対応方法は、プログラムで内部向きに利用するgRPC Clientにおけるmetadataの値に対し、リクエストとして受信した X-Amzn-Trace-Id の追加許可処理を実装しました。
BigQueryでのログ分析への影響調査は「苦労したこと」で記載します。
ログ調査基盤の構築
採用を検討した基盤
トレースIDが解決したので、今後はログ調査のプラットフォームを検討しました。
ココナラでは以下の3つを比較しています。
- Amazon Athena
- ElasticSearch on ElasticCloud
- Amazon OpenSearch Service
前述の通り、「QCDの観点でDelivery(納期)を最優先にしたかった」という背景から、最短で構築できると見込んだAmazon Athenaを採用しました。
ただし、機能面ではAmazon Athenaの特性上、AIによる提案やグラフを用いた可視化への対応には弱いという課題もあります。
ですが、Amazon Athenaの導入だけでログ調査・分析に費やす時間を半分以下に減らすことができました。
そのため、最短で結果が出る方法でシステムを構築したことは、結果的には良い判断だったと思います。
ログ調査基盤導入前後の構成
ログ調査基盤は、下記のようにログの格納先をS3中心として構築しました。
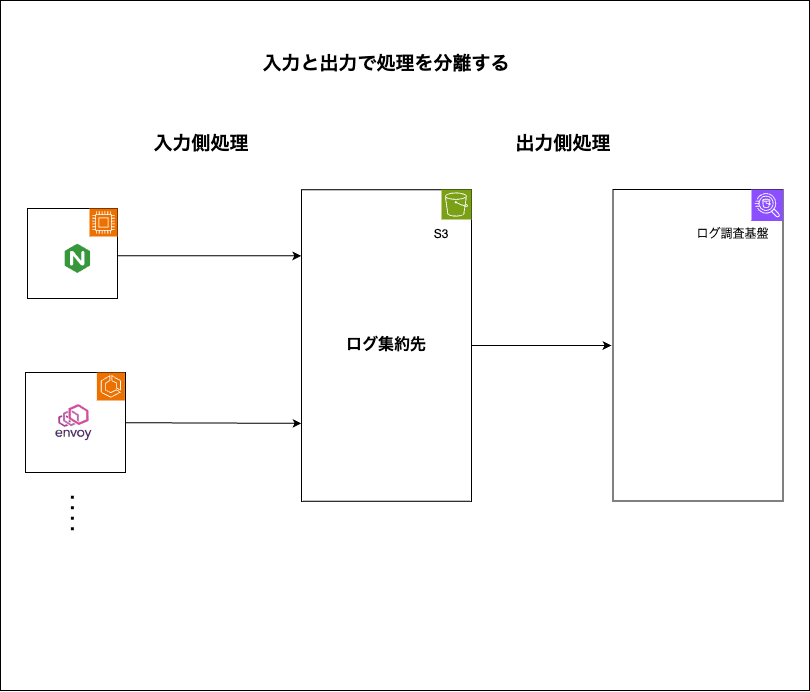
S3を保存先として活用する理由は以下の2つになります。
- 入力のログの保存処理と出力のログの利用処理を並列化
- ログの保存先をCloudWatchからS3に移行することによるコスト削減
今までは以下のような環境でログ調査・分析を行っていました。
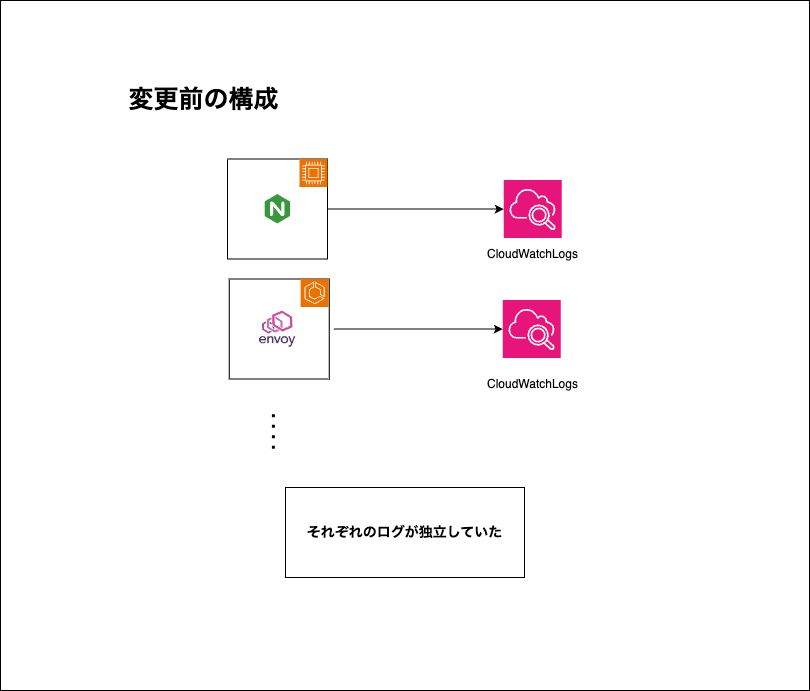
ログ調査基盤導入前のアクセスログを扱うシステム構成
この構成では、ログの形式が異なる場合に横断調査がしにくいです。(ここでのログの形式は、TSV(Tab Space Value)やjsonなどを指します)
ログの形式が混ざってしまった場合においては、調査は部分一致のみに頼らざるを得ず、TSVとjsonデータで同じフィールドのデータを同等に扱うことができないことが課題でした。
ログ調査基盤構築後は以下のような環境でログ調査・分析を行っています。

変更後のアクセスログを扱うシステム構成
この構成では、各ログの情報をデータベースのように扱えます。
そのため、ログ情報を横断して調査を行う際、期待したカラム情報だけを正確に扱えるようになり、調査に対しての正確さが増しました。
それによって、ログ調査時間の短縮や効率化を行うことができました。
苦労したこと
既存の仕組みへの影響確認
主に苦労したのは以下の2点です。
- BigQueryへのログ転送はfluentdを利用しているが、fluentdのナレッジが残っていなかった
- BigQueryへの転送設定は入力時のタグにより決まるように設定されている
- fluentdの転送設定が本番環境と開発環境で差分がある
まずはソースコードから過去のメモ書きまで集められる情報を集めるところから始めました。
次に検証環境を用いて、fluentdへの入力時のタグ毎を検証する一単位とし、URLやAPIのパスへのアクセスを実施し、実際の転送を確認しました。
今回の検証は数パターンでしたので、愚直な手動対応で完遂することができました。
効果
調査を効率的・効果的にできるようになった
繰り返しではありますが、調査時間が利用前の半分以下になりました。
ログから日時とIDを入力し、調査開始のボタンひとつで、素早く調査が行えるようになりました。
具体的には、ログ調査基盤を利用することにより、 トレースIDとして設定した X-Amzn-Trace-Id を基に情報を検索することで、システム全体のログから一致した情報が一度に表示されます。
そのため、中間のログの内容を確認することなく、目的のログを探すことができるようになりました。
より深堀りを行うことが可能となった
以前もユニークなIDはログに記録されておりましたが、1リクエストを一気通貫で追いかけることができなかったです。
そのため、特定の画面や特定の操作のみといった、局所的に生じるエラーでは、相対的にエラーの原因調査がし難い傾向にありました。
ログ調査基盤では、1リクエストの中で生じたログにのみ、調査範囲を絞り表示できます。
調査結果を用いることで、アクセスしたパスを細かく追えるようになりました。
結果、エラーの原因となったコードの特定や影響範囲の特定をすばやく行えるようになりました。
まとめ
アクセスログのログ調査基盤を導入したことにより、調査対応が格段に早く対応できるようになりました。
開発環境にも導入したことにより、期待通り開発中のシステムが動作しないことへの調査の労力が減りました。
具体的には、以下の手順にてシステムで発生したエラー状況を調査できます。
- トレースIDとタイムスタンプを、ログにて確認する
- 上記で得られたトレースIDと日時を用い、事前に用意した調査用クエリを、ログ調査基盤にて実行する

アクセスログのトレースIDを用いてエラー状況を調査した例
最後に
ココナラでは一緒に事業を推進していただけるエンジニアを募集しています。
SRE領域だけでなく、フロントエンド領域・バックエンド領域などでも積極的にエンジニア採用を行っています。
少しでも興味を持たれた方がいましたら、エンジニア採用ページをご覧ください。
SREも募集していますので、ぜひご覧ください。
Discussion