データ戦略室で室長かつデータサイエンティストをしている阪上です。今回は統計学のことをもっと伝えたくて10個の事例について記しました。
『統計学で嘘をつく法』という本がありますが、人々に間違った解釈を与える以上、統計学は便利である反面、罪深いものでもあります。ビジネスの世界でデータサイエンティスト業を生業としているものとしては誤解や誤用とは向き合い続けていきたいです。
統計学などの知識を正しく理解して使うというのは中々難しいと思います。先日読んだ『統計学再入門』という書籍にも記されているように、科学者ですら誤用や誤解が蔓延しているとされる統計学において、ビジネスの世界でも誤用されないわけがないと思われます。
そこで、私が過去にビジネスを進める上で観察した統計学の誤用と、観察はしていないが良くありそうな誤用について記してみたいと思います。両者を混ぜることにより、社内で実際に生じたエピソードを特定することは難しいはずです。データ分析の民主化がある程度進むと、思いがけない統計学の誤用が生じてもおかしくありません。失敗事例を共有するのはあまり気持ちのいいものではないですが、失敗からの学びをこのブログを読まれる方に届けることができれば幸いです。 ちなみに、とても細かいですが、「母数」という表現はもはや正しく使われることは厳しいと思います。社内のみならず世の中で書かれた書物の段階で誤用があるため、この流れを止めることは中々に難しいと思います。
その1. データ数が少ししかないのに決定係数を出して当てはまりがいいと言っている事例
このケースだと、例えばデータは年齢・コンバージョン有無(以下、CV)としましょう。年齢階級を20~70代で6つ作るものとします。データは1000件作りました。

(今回だと乱数で生成しているので、年齢とCVの相関関係はありません。)
年齢階級ごとのCVの割合を集計するのは特に何の問題もありません。ただ、私が驚いたのは、散布図に集計した値をプロットし、その回帰直線の決定係数の高さ(0.7以上)をさもありなんと報告しているレポートでした。生データではほとんど相関していないが変換を施すことで相関するとしているわけですが、これはデータ数が6つで回帰していることに相違ないので、データの傾向が変わるとロバストな結果にはならないと思います。

(集計値を散布図にプロットして、回帰直線を引いたケースの例)
ただし、たちが悪いのはこれらを相関係数の有意性検定をしてしまうと、P値が5%以下になります。そのため、このたった6つの点列で統計的なお墨付きを得たとして意思決定に使ってしまうというユースケースがあるのだろうと思います。 私としては、たった6つのデータで意思決定をするのは危険だと思うので、統計的に有意な差があるとされても、サンプルをもっと集めていくなどをしたいです。 なんなら、今回のケースは元データが1000件もあるのですから、CVの0-1データを用いてロジスティック回帰にして、その年齢の係数がどうなのかを見ていくのも良いと思います。
その2. カイの二乗検定で差がつくまで広告を出し続けて投資の正当性を言おうとする事例
このケースは、あるデザインのバナー広告についてそれなりの費用がかかったので、統計的に差があるような結果がもたらされたかどうかを報告しようとしているものです。
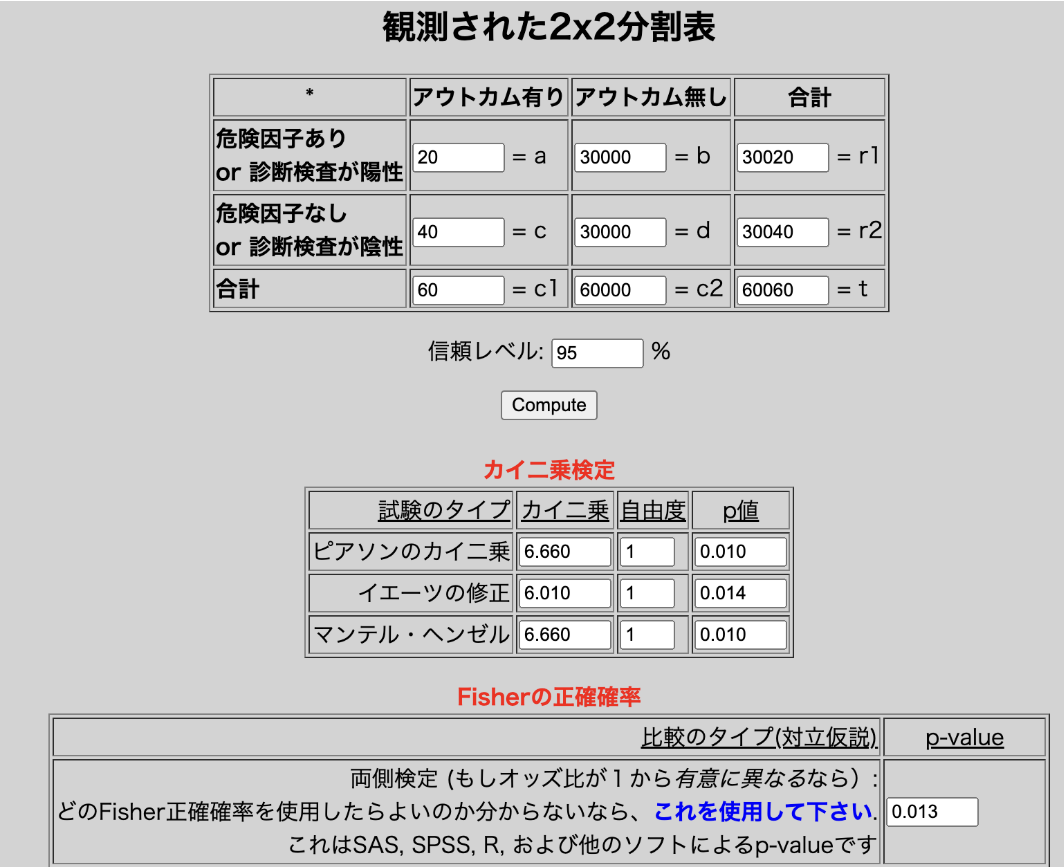
(0.0数%の違いしかないが、統計的に有意な差がつく例)
よくあるのが、「差が出るまでバナー広告を出稿します」という流れで、いたずらにデータ数が増え、ほんの0.数%の差で有意差がついたとして広告出稿の正当性を示そうとすることです。統計学に明るいこのブログの皆さんにとっては言及する必要はありませんが、データ数が増えれば増えるだけ統計検定における有意差がつくようなCVRなどの差分は小さくなります。有意差という謎のお墨付きを得ようとするがために、多大な時間とコストをかけるのは避けたいところです。0.0数%よりももっと高い効果が期待できる他の施策が存在する可能性があるのですから。 近年では、効果量を事前に想定し、規定のサンプル数になるまで広告出稿をするなどビジネス的にメイクセンスな方向で統計検定が使われているので、このような事例を見かけることはなくなってきました。
その3. 当てはまりがよくなるように恣意的にハイパーパラメータを調整する事例
これは統計モデリングと機械学習の違いだと思うのですが、機械学習ではクロスバリデーションを厳格に行い、訓練データ・検証データ・テストデータをきっちりと扱い汎化性能を高めることができる限りにおいては、リークを避けた上でパラメータをいじり倒して精度向上を目指すことになんの問題もないというか、むしろそうであるべきと言うくらいに自動で最適なものを選ぶことが妥当だと考えています。もちろん、露骨な過学習は避けるべきですが、統計モデリングよりも汎化性能の名の下に、ある程度の自由さがあると思われます。 他方、統計モデリングは仮説ありきで慎重にそのデータが、ある一定の条件のもとで被説明変数に影響を与えるのかを見て、一般的な傾向を捉えるものです。 よくない事例だと、データを所与のもとで事前分布などのハイパーパラメータを当てはまりが良くなるように試行錯誤してしまうケースです。本来だと仮説検証を重視すべきところを目的関数の最小化などに振り切ってしまった結果で、一般化したいという目指すべき姿を見失ってしまい、起きてしまうのかなと思います。『StanとRでベイズ統計モデリング』という書籍で学んでいくと、統計モデリングの作法が身につきますが、非データサイエンティストにそれらの理解を求めるのは現実的ではないかもしれません。
その4. 学習データとテストデータに同じユーザーの情報が含まれて精度が高そうに見えた事例
これは統計学ではないですが、頻出なので記そうと思います。私自身も社内のデータで機械学習をする際は、分析の初手では気付けずに犯してしまうこともあるのですが、何かを機械学習する際に、データセットによっては学習用データとテストデータに同じユーザーが含まれうることがあります。 例えば、あるユーザーがコンバージョンしにくい特徴があったとして、それを学習するとします。全く同じユーザーがテストデータにあると、それは予測しやすいと言う観点から、不当に性能が高いと見えることがあります。これに関してはあらゆる機械学習系のタスクで発生する可能性があるので、分析のレビューでは必ず確認するようにしています。
その5. 単位根検定を行わず時系列同士で回帰をしている事例
この事例は統計学で回帰分析を覚えてなんでも回帰したくなるビギナーなかたにおいて起きがちな事例です。分析のレビューを挟んでいただければ単位根検定を案内できるのですが、挟まない場合はその限りではありません。単位根がある場合、説明変数と被説明変数が関係なくても有意な差がついてしまう可能性があります。単位根がある場合はそれに応じた対応策をして分析をしなければなりません。 回帰分析を学ぶ教材では確実に抱き合わせで教えて欲しいと思ってしまいます。
その6. P値の大きさで序列をつけて評価している事例
有意差の有無を決める数値であることからか、P値の大きさで序列を付けて物事の意思決定をしようとするケースを何度か目にしたことがあります。 P値は効果の大きさを示すものではなく、仮説検定の目的で使われるものなので、今後もこのような使われ方を目撃したら阻止したいですね。 よく、Xの界隈では「人類に統計学は早過ぎたのではないか」と盛り上がることもありますが、有意差の有無というものにこだわってしまった結果、本来の用途を度外視してしまうのかもしれません。
その7. 重回帰の係数の結果は、ANDでなくてOR条件
これは初めて重回帰分析をやっている方々にありがちなのですが、説明変数の係数において有意な差が二つ出ていたとして、そのどちらも満たす事例を考えがちです。 どちらか一方の影響と見なすのが正しく、どちらも満たす事例の有意差を知りたい場合は、クロスしたダミー変数を作るなどの必要があります。

(社内で行っている統計学の講座の資料の例)
その8. 打ち切りデータをそのまま回帰
こちらに関しても、やはり手元にデータがあると回帰したくなる衝動に駆られるかたもおられると思いますが、打ち切りが発生するようなデータ(年収、売上など)をそのまま回帰してしまうと推定結果にバイアスが入ってしまいます。そのようなアプローチで得られた結果で意思決定をしてしまうのは避けたい限りです。 ノーベル賞を受賞したトービンが考案したトービットモデルやヘックマンのヘックマンの 2 段階推定法(ヘキット)を使うことで打ち切りデータのバイアスに向き合うことが可能になりますが、入門書にはそのようなアプローチは記されていないことが多いです。

(Chat-GPTで生成:従属変数が20で打ち切られているが、真の値は赤のプロット)
その9. 多重比較で見つかった、商談確率が高くなるミーティングルーム
これは失敗事例ではないですが、機械学習でお客様との商談の成否をスコアリングしようとした際に、なんとなく商談に用いたミーティングルームもデータとして繋げることができたため、興味本位で分析をしてみたのですが、数十個のミーティングルームがあったことから、カイ二乗検定で統計的に有意な差がつくような、商談が成功しやすいミーティングルームが出てきてしまいました。「このMTGルームを使えば、商談が成功する!」というのは大変に滑稽な話です。流石に、このような誤りをして意思決定を見たことはないですが、有意差が出てしまうので、注意したいですね。 EDAで個々のデータと商談との関係が独立かどうかを見る分にはいいですが、多重比較により見つけた、有意な差が出てしまった組み合わせを真に受けるのは避けたいですね。仮に多重比較に関する補正をしたとしても、「このMTGルームを使えば、商談が成功する」は示したくないですが。
その10.君は残差プロットを見たか
データサイエンティストではない方が行う回帰分析などで、残差プロットを確かめているケースをあまり見かけることがありません。これは、ガウスが考えた「最小二乗法は残差が正規分布に従う」ことが重要な仮定として置かれているという前提を軽んじています。残差プロットを確認して、残差に傾向がある場合は重要な仮定が崩れている以上、その統計モデルを意思決定に使うのは望ましくありません。200年前に手法を考えてくれたガウスに説教されてしまうかもしれませんね。

(残差プロットの例:R言語で描画(横軸は某人気モンスターRPGのモンスターのID))
おわりに
以上、数々の事例でビジネスの世界で正しく統計学が使われるのは中々難しいことであるということが伝わったでしょうか。 私は統計学は人類には早過ぎたとまでは思わないですが、統計的に有意な差を出したいという目に見えないプレッシャーのようなものが正しく学ぶ冷静さを失わせているのではないかと思うことがあります。データサイエンティストとしては引き続き正しく分析技術が使われるようにレビューをしていきたいと思います。 また、回帰分析を初めて教える際に、このアプローチが銀の弾丸ではないと伝えた上で、残差プロット・単位根・打ち切りデータなど周辺知識をしっかりと伝えていかないといけないのだろうと思います。
参考情報
・”4.5 相関の有意性”, https://www2.lowtem.hokudai.ac.jp/climbsd/group/shigeru/tc/datan2007/z4cor.pdf
・”2x2分割表解析”, http://aihara-hp.la.coocan.jp/grade-com/2x2.html
・北村行伸, ”第10章 トービット・モデルとヘックマン の2段階推定: 労働供給問題”, https://www.ier.hit-u.ac.jp/~kitamura/lecture/Hit/08Statsys10.pdf
・池田郁男(2019) , ”改訂増補版: 統計検定を理解せずに使っている人のためにIII”, https://www.jstage.jst.go.jp/article/kagakutoseibutsu/57/10/57_571007/_pdf/-char/ja